Casas de california
Modelo de Machine Learning que ayuda a predecir el valor de una casa en California dependiendo ciertos factores
Descripción del conjunto de datos
Primeras 5 filas del conjunto de datos
housing = pd.read_csv("data/housing.csv")
housing.head()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 | NEAR BAY |
| 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 | NEAR BAY |
| 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 | NEAR BAY |
| 3 | -122.25 | 37.85 | 52.0 | 1274.0 | 235.0 | 558.0 | 219.0 | 5.6431 | 341300.0 | NEAR BAY |
| 4 | -122.25 | 37.85 | 52.0 | 1627.0 | 280.0 | 565.0 | 259.0 | 3.8462 | 342200.0 | NEAR BAY |
Información del conjunto de datos
housing.info()
| # | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | longitude | 20640 non-null | float64 |
| 1 | latitude | 20640 non-null | float64 |
| 2 | housing_median_age | 20640 non-null | float64 |
| 3 | total_rooms | 20640 non-null | float64 |
| 4 | total_bedrooms | 20433 non-null | float64 |
| 5 | population | 20640 non-null | float64 |
| 6 | households | 20640 non-null | float64 |
| 7 | median_income | 20640 non-null | float64 |
| 8 | median_house_value | 20640 non-null | float64 |
| 9 | ocean_proximity | 20640 non-null | object |
| dtypes: float64(9), object(1) |
Podemos observar que la columna “total_bedrooms” tiene 207 valores nulos y la columna “ocean_proximity” es de tipo objeto, ya que leímos los datos desde un csv podemos inferir que son de tipo texto.
Veremos el contenido de la columna “ocean_proximity”
housing['ocean_proximity'].value_counts()
| 1H OCEAN | 9136 |
| INLAND | 6551 |
| NEAR OCEAN | 2658 |
| NEAR BAY | 2290 |
| ISLAND | 5 |
| Name: ocean_proximity | dtype: int64 |
Al parecer la columna “ocean_proximity” es una variable categórica de 5 niveles
Ahora generaremos las estadísticas descriptivas del conjunto de datos
housing.describe()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20433.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 |
| mean | -119.569704 | 35.631861 | 28.639486 | 2635.763081 | 537.870553 | 1425.476744 | 499.539680 | 3.870671 | 206855.816909 |
| std | 2.003532 | 2.135952 | 12.585558 | 2181.615252 | 421.385070 | 1132.462122 | 382.329753 | 1.899822 | 115395.615874 |
| min | -124.350000 | 32.540000 | 1.000000 | 2.000000 | 1.000000 | 3.000000 | 1.000000 | 0.499900 | 14999.000000 |
| 25% | -121.800000 | 33.930000 | 18.000000 | 1447.750000 | 296.000000 | 787.000000 | 280.000000 | 2.563400 | 119600.000000 |
| 50% | -118.490000 | 34.260000 | 29.000000 | 2127.000000 | 435.000000 | 1166.000000 | 409.000000 | 3.534800 | 179700.000000 |
| 75% | -118.010000 | 37.710000 | 37.000000 | 3148.000000 | 647.000000 | 1725.000000 | 605.000000 | 4.743250 | 264725.000000 |
| max | -114.310000 | 41.950000 | 52.000000 | 39320.000000 | 6445.000000 | 35682.000000 | 6082.000000 | 15.000100 | 500001.000000 |
Graficaremos un histograma de cada columna
housing.hist(bins=50, figsize=(20,15))
plt.show()
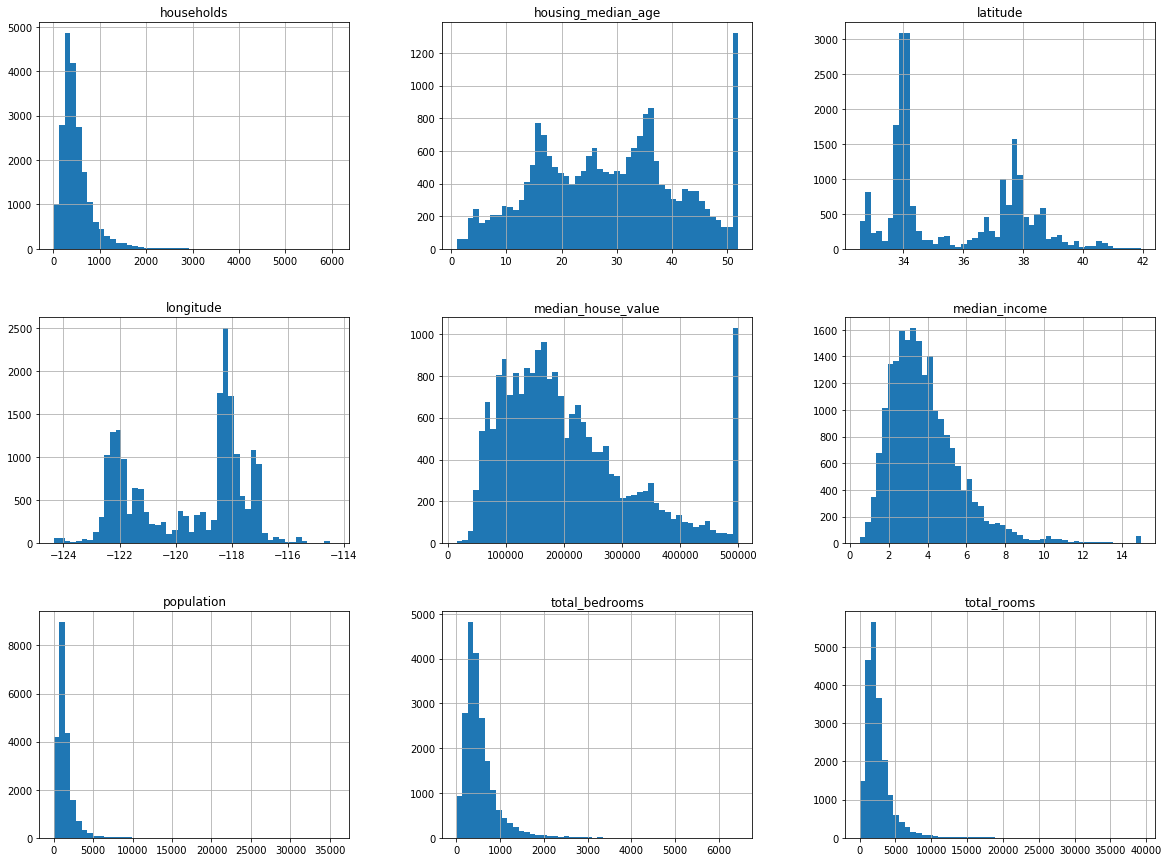
Se pueden observar varias cosas en estos histogramas
- El ingreso medio no parece expresado en dolares. Los datos fueron escalados y limitados a 15 para grandes ingresos medios, y a 5 para los ingresos medios más bajos. Los números representan decenas de miles de dolares.
- La edad media de la vivienda y el valor medio de la vivienda también fueron limitados.
- Los atributos tienen escalas muy diferentes.
- Varios histogramas tienen una larga cola: Se extienden más a la derecha de la mediana que a la izquierda.
Crear conjunto de pruebas
Segmentaremos y clasificaremos la columna “median_income” en 5 contenedores. De esta forma crearemos una columna categórica que nos servirá para separar los datos equitativamente.
housing["income_cat"] = pd.cut(housing["median_income"],
bins=[0., 1.5, 3.0, 4.5, 6., np.inf],
labels=[1, 2, 3, 4, 5])
housing["income_cat"].value_counts()
| 3 | 7236 |
| 2 | 6581 |
| 4 | 3639 |
| 5 | 2362 |
| 1 | 822 |
| Name: income_cat | dtype: int64 |
Ahora crearemos separaremos el conjunto de pruebas usando la nueva columna categórica.
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
Comprobaremos que ambos conjuntos tienen la misma proporción de ingresos medios.
strat_test_set["income_cat"].value_counts() / len(strat_test_set)
| 3 | 0.350533 |
| 2 | 0.318798 |
| 4 | 0.176357 |
| 5 | 0.114583 |
| 1 | 0.039729 |
| Name: income_cat | dtype: float64 |
housing["income_cat"].value_counts() / len(housing)
| 3 | 0.350581 |
| 2 | 0.318847 |
| 4 | 0.176308 |
| 5 | 0.114438 |
| 1 | 0.039826 |
| Name: income_cat | dtype: float64 |
Podemos observar que ambos conjuntos tienen una proporción similar.
Procederemos a eliminar la columna categórica que creamos.
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)
Visualizar los datos
housing = strat_train_set.copy()
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population", figsize=(10,7),
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,
)
plt.legend();
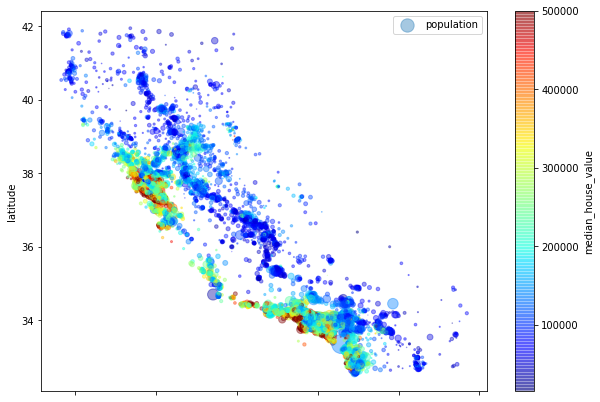
Podemos apreciar que las casas con un mayor precio están ubicadas cerca de la costa
Buscar correlaciones
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
El coeficiente de correlación se distribuye de -1 a 1, si el valor es cercano a -1 significa que dos columnas tienen una correlación negativa, si es cercano a 1 significa que dos columnas tienen una correlación positiva, si el valor es 0 significa que no existe una correlación entre las dos columnas.
| median_house_value | 1.000000 |
| median_income | 0.687160 |
| total_rooms | 0.135097 |
| housing_median_age | 0.114110 |
| households | 0.064506 |
| total_bedrooms | 0.047689 |
| population | -0.026920 |
| longitude | -0.047432 |
| latitude | -0.142724 |
| Name: median_house_value | dtype: float64 |
Ya que “median_house_value” es la columna que estamos evaluando da 1 exacto, la columna que tiene una mayor correlación es “median_income” lo que nos dice que las casas con un mayor precio en un vecindario son aquellas cuyos residentes tienen un ingreso medio mayor.
Graficaremos las 3 columnas con una mayor correlación, para intentar apreciarlo mejor
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8));
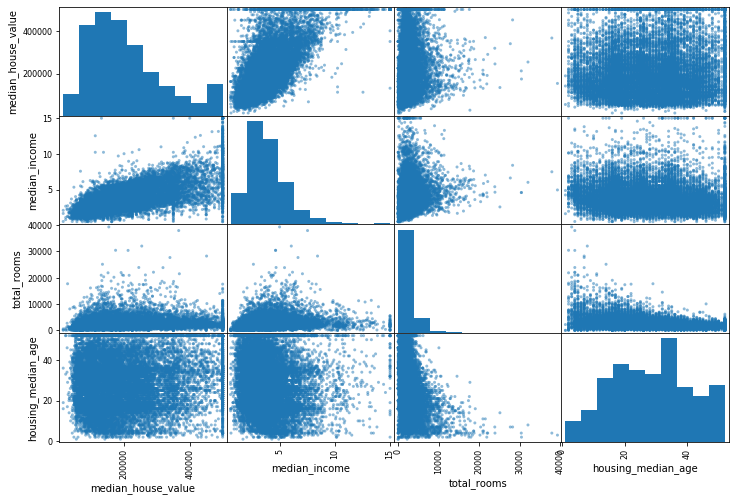
Ahora nos centraremos a la gráfica con una mayor correlación “median_house_value”
housing.plot(kind="scatter", x="median_income", y="median_house_value",
alpha=0.1);
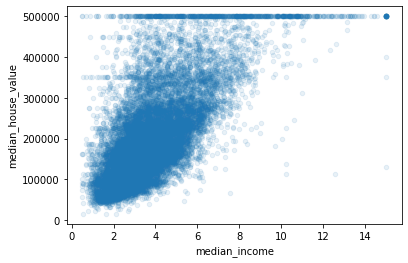
Esta gráfica revela unas cuantas cosas. Primero, la correlación es muy fuerte; puedes ver claramente la tendencia y los puntos no están muy dispersos. Segundo, el límite de precio es claramente visible como una línea horizontal a los \$500,000, pero también se revelan otras líneas menos obvias: una línea horizontal alrededor de \$450,000, otra alrededor de \$350,000, y tal vez una alrededor de \$280,000 y algunas debajo de eso.
Experimentar con combinaciones de atributos
Crearemos nuevas columnas para intentar buscar algunas con mayor correlación
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
| median_house_value | 1.000000 |
| median_income | 0.687160 |
| rooms_per_household | 0.146285 |
| total_rooms | 0.135097 |
| housing_median_age | 0.114110 |
| households | 0.064506 |
| total_bedrooms | 0.047689 |
| population_per_household | -0.021985 |
| population | -0.026920 |
| longitude | -0.047432 |
| latitude | -0.142724 |
| bedrooms_per_room | -0.259984 |
| Name: median_house_value | dtype: float64 |
El nuevo atributo “bedrooms_per_room” está más correlacionado con el valor medio de las viviendas que el número de habitaciones o dormitorios. Aparentemente casas con un ratio dormitorios/habitaciones más bajo tienden a ser más caras. El atributo “rooms_per_household” es más informativo que el total de habitaciones en un distrito - obviamente las casas más grandes son más caras
Preparar los datos
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()
Limpieza de datos
Primero nos encargaremos de los valores nulos, rellenaremos esos valores con la mediana de la columna
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
Ya que el SimpleImputer solo puede trabajar con valores numéricos retiraremos la columnas no numéricas
housing_num = housing.drop("ocean_proximity", axis=1)
Ahora crearemos el imputer
imputer.fit(housing_num)
Valores que usará el imputer para rellenar las columnas
imputer.statistics_
| -118.51 | 34.26 | 29.0 | 2119.5 | 433.0 | 1164.0 | 408.0 | 3.5409 |
Aplicaremos el imputer
X = imputer.transform(housing_num)
housing_tr = pd.DataFrame(X, columns=housing_num.columns)
Ahora nos encargaremos de las columnas categóricas, en este caso “ocean_proximity”
housing_cat = housing[["ocean_proximity"]]
housing_cat.head(10)
| ocean_proximity | |
|---|---|
| 17606 | <1H OCEAN |
| 18632 | <1H OCEAN |
| 14650 | NEAR OCEAN |
| 3230 | INLAND |
| 3555 | <1H OCEAN |
| 19480 | INLAND |
| 8879 | <1H OCEAN |
| 13685 | INLAND |
| 4937 | <1H OCEAN |
| 4861 | <1H OCEAN |
Usaremos el algoritmo OneHotEncoder para crear una columna por cada nivel de la variable categórica, si una fila pertenece a un nivel entonces el valor que tendrá en la columna será 1 en otro caso será 0
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
Crearemos una clase que nos permita automatizar la inclusion de la nueva columna que creamos anteriormente, gracias a esta clase podremos darnos una idea si perjudica o ayuda al modelo.
from sklearn.base import BaseEstimator, TransformerMixin
# column index
rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X):
rooms_per_household = X[:, rooms_ix] / X[:, households_ix]
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)
Le echaremos un vistazo a la nueva tabla
housing_extra_attribs = pd.DataFrame(
housing_extra_attribs,
columns=list(housing.columns)+["rooms_per_household", "population_per_household"],
index=housing.index)
housing_extra_attribs.head()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | ocean_proximity | rooms_per_household | population_per_household | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 17606 | -121.89 | 37.29 | 38 | 1568 | 351 | 710 | 339 | 2.7042 | <1H OCEAN | 4.62537 | 2.0944 |
| 18632 | -121.93 | 37.05 | 14 | 679 | 108 | 306 | 113 | 6.4214 | <1H OCEAN | 6.00885 | 2.70796 |
| 14650 | -117.2 | 32.77 | 31 | 1952 | 471 | 936 | 462 | 2.8621 | NEAR OCEAN | 4.22511 | 2.02597 |
| 3230 | -119.61 | 36.31 | 25 | 1847 | 371 | 1460 | 353 | 1.8839 | INLAND | 5.23229 | 4.13598 |
| 3555 | -118.59 | 34.23 | 17 | 6592 | 1525 | 4459 | 1463 | 3.0347 | <1H OCEAN | 4.50581 | 3.04785 |
Crearemos una pipeline que nos permita hacer todo el pre-procesamiento anterior de una forma más cómoda, primero nos enfocaremos a las columnas numéricas, aprovecharemos para estadarizar los valores de las columnas.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
Ahora crearemos una pipeline para todo el conjunto de datos
from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(housing)
Seleccionar un modelo y entrenarlo
Entrenamiento y evaluación en el conjunto de entrenamiento
Probaremos varios modelos para encontrar el que tenga mejores resultados
Primero intentaremos con un modelo de regresión lineal
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
Intentaremos hacer unas cuantas predicciones con este modelo
# let's try the full preprocessing pipeline on a few training instances
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
print("Predictions:", lin_reg.predict(some_data_prepared))
print("Labels:", list(some_labels))
| Predictions | 210644.60 | 317768.80 | 210956.43 | 59218.98 | 189747.55 |
|---|---|---|---|---|---|
| Labels | 286600.00 | 340600.00 | 196900.00 | 46300.00 | 254500.00 |
Ahora que tenemos tanto los valores predichos como los valores reales usaremos algunas métricas para evaluar el rendimiento del modelo
Primero provaremos el error medio cuadrado
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
| lin_rmse | 68628.19 |
|---|
Ahora probaremos con el error medio absoluto
from sklearn.metrics import mean_absolute_error
lin_mae = mean_absolute_error(housing_labels, housing_predictions)
| lin_mae | 49439.89 |
|---|
Ahora probaremos un árbol de decisión
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(random_state=42)
tree_reg.fit(housing_prepared, housing_labels)
Ya que tenemos el modelo creado lo usaremos para hacer predicciones y verificar su rendimiento
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
| tree_rmse | 0.00 |
|---|
El cuadrado medio nos dio un resultado 0, lo cual significa que el modelo acertó todas las predicciones, sin embargo esto puede implicar que el modelo se haya sobreajustado, lo que nos dice que aunque haya acertado en el conjunto de entrenamiento es posible que falle con nueva información
Evaluación usando Cross validation
Ya que el modelo parece que sobreajustó las predicciones usaremos un algoritmo que divide el conjunto en cierto número de partes iguales, en nuestro caso lo dividiremos en 10 partes, entonces entrena el modelo con 9 de las partes y hace las predicciones con la parte restante, esto la hará 10 veces, tomando diferentes partes cada vez.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
Ya que tenemos calculados los valores los imprimiremos
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
display_scores(tree_rmse_scores)
| Scores | 70194.33 | 66855.16 | 72432.58 | 70758.73 | 71115.88 |
|---|---|---|---|---|---|
| 75585.14 | 70262.86 | 70273.63 | 75366.87 | 71231.65 | |
| Mean | 71407.68 | ||||
| Standard deviation | 2439.43 |
Haremos lo mismo con la regresión lineal
lin_scores = cross_val_score(lin_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
lin_rmse_scores = np.sqrt(-lin_scores)
display_scores(lin_rmse_scores)
| Scores | 66782.73 | 66960.11 | 70347.95 | 74739.57 | 68031.13 |
|---|---|---|---|---|---|
| 71193.84 | 64969.63 | 68281.61 | 71552.91 | 67665.10 | |
| Mean | 69052.46 | ||||
| Standard deviation | 2731.67 |
Ahora probaremos un bosque aleatorio
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor(n_estimators=100, random_state=42)
forest_reg.fit(housing_prepared, housing_labels)
housing_predictions = forest_reg.predict(housing_prepared)
forest_mse = mean_squared_error(housing_labels, housing_predictions)
forest_rmse = np.sqrt(forest_mse)
| forest_rmse | 18603.51 |
|---|
from sklearn.model_selection import cross_val_score
forest_scores = cross_val_score(forest_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
forest_rmse_scores = np.sqrt(-forest_scores)
display_scores(forest_rmse_scores)
| Scores | 49519.80 | 47461.91 | 50029.02 | 52325.28 | 49308.39 |
|---|---|---|---|---|---|
| 53446.37 | 48634.80 | 47585.73 | 53490.10 | 50021.58 | |
| Mean | 50182.30 | ||||
| Standard deviation | 2097.08 |
Parece ser que el modelo que mejor rindió fue el del bosque aleatorio
Ahora que tenemos nuestro modelo lo afinaremos para que de mejores resultados, para eso usaremos GridSearchCV para encontrar el valor de los hyper-parametros más adecuado
from sklearn.model_selection import GridSearchCV
param_grid = [
# try 12 (3×4) combinations of hyperparameters
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
# then try 6 (2×3) combinations with bootstrap set as False
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor(random_state=42)
# train across 5 folds, that's a total of (12+6)*5=90 rounds of training
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error',
return_train_score=True)
grid_search.fit(housing_prepared, housing_labels)
Ahora veremos cual es la mejor combinación de hyper-parametros
grid_search.best_params_
| max_features | 8 |
|---|---|
| n_estimators | 30 |
| bootstrap | True |
Calcularemos el error medio cuadrado para cada combinación de hyper-parametros para verificar que la combinación sea correcta
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
| mean_squared_error | bootstrap | max_features | n_estimators |
|---|---|---|---|
| 63669.11 | True | 2 | 3 |
| 55627.09 | True | 2 | 10 |
| 53384.57 | True | 2 | 30 |
| 60965.95 | True | 4 | 3 |
| 52741.04 | True | 4 | 10 |
| 50377.40 | True | 4 | 30 |
| 58663.93 | True | 6 | 3 |
| 52006.19 | True | 6 | 10 |
| 50146.51 | True | 6 | 30 |
| 57869.25 | True | 8 | 3 |
| 51711.12 | True | 8 | 10 |
| 49682.27 | True | 8 | 30 |
| 62895.06 | False | 2 | 3 |
| 54658.17 | False | 2 | 10 |
| 59470.40 | False | 3 | 3 |
| 52724.98 | False | 3 | 10 |
| 57490.56 | False | 4 | 3 |
| 51009.49 | False | 4 | 10 |
Ahora buscaremos las columnas que aportan más al modelo, en otras palabras, las columnas que afectan más al precio de una vivienda
feature_importances = grid_search.best_estimator_.feature_importances_
feature_importances
| feature_importances | 7.334e-02 | 6.290e-02 | 4.114e-02 | 1.467e-02 |
|---|---|---|---|---|
| 1.410e-02 | 1.487e-02 | 1.425e-02 | 3.661e-01 | |
| 5.641e-02 | 1.087e-01 | 5.335e-02 | 1.031e-02 | |
| 1.647e-01 | 6.028e-05 | 1.960e-03 | 2.856e-03 |
Obtuvimos lo que afecta cada columna en el precio, sin embargo nos falta anotar cada columna con su valor.
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
#cat_encoder = cat_pipeline.named_steps["cat_encoder"] # old solution
cat_encoder = full_pipeline.named_transformers_["cat"]
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True)
| 0.3661 | median_income |
| 0.1647 | INLAND |
| 0.1087 | pop_per_hhold |
| 0.0733 | longitude |
| 0.0629 | latitude |
| 0.0564 | rooms_per_hhold |
| 0.0533 | bedrooms_per_room |
| 0.0411 | housing_median_age |
| 0.0148 | population |
| 0.0146 | total_rooms |
| 0.0142 | households |
| 0.0141 | total_bedrooms |
| 0.0103 | <1H OCEAN |
| 0.0028 | NEAR OCEAN |
| 0.0019 | NEAR BAY |
| 6.0280e-05 | ISLAND |
Ahora probaremos nuestro modelo con el conjunto de pruebas que separamos en un principio
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
| final_rmse | 47730.22 |
|---|
El resultado final nos dice que nuestro modelo puede predecir el valor de una casa en California con un margen de error de $47,730.22
Para ver el repositorio completo ¡Click aquí!